前言:在云厂的工作中,总是会面对大量的时序数据。InfluxDB 是工作中最常用的时序数据库。时序数据与更为常用的关系数据的区别是什么,为什么 InfluxDB 可以高性能低存储空间消耗的存储海量时序数据。
一、用户故事
时序数据有什么特点?分析一个具体的需求:如何存储一个数据中心内所有服务器 CPU 分核心使用率?
就是需要表达:设备在某个时间的状态。
打开任务管理器,切换到性能 Tab,就可以看见自己设备的 CPU 使用率图。
只看其中 CPU 占用率的图,如果把它还原成表的形式:
| IP地址 | CPU核 | 时间 | 使用率 |
| 192.168.1.1 | #0 | 5 | 1 |
| 192.168.1.1 | #1 | 5 | 17 |
| 192.168.1.1 | #0 | 6 | 3 |
| 192.168.1.1 | #1 | 6 | 15 |
可以归类为:
- IP地址、CPU核:共同表达了是哪一个设备,把这些统称为标签
- 时间
- 使用率:设备的状态,即值
这就是时序数据的基本数据模型。
对比常见的用户表:
| 用户名 | 密码 | 上次登陆时间 |
| tsrs | $2a$10$Tf9Qw0W8UOW2P…… | 5 |
| rsts | $2a$10$EvLK4wtA4xSHYU…… | 10 |
发现时序数据会有这些特点:
- 一定会存在时间及值
- 标签会经常重复,因为一个设备会持续的产生数据,同一个设备的标签是一致的。
数据操作的需求:
- 增:批量增,所有的设备会间隔 1s 上报自己的 CPU 使用率
- 删:区间删,删除 7 天之前的所有数
- 改:不会改,不会出现「把 4 月份的CPU使用率改为 0」的情况
- 查:时间区间+标签查,找出过去十分钟 192.168.1.1 CPU#0 核的使用率
对比用户系统:
- 增:单条增,注册
- 删:单条删,销户
- 改:单条改,改密
- 查:单条查,登录
然后是计算机本身的特点:
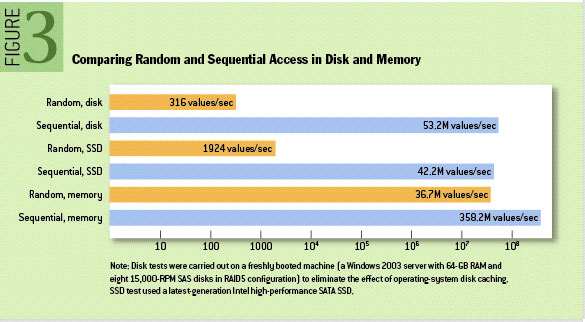
无论是HDD、SSD还是内存连续读写性能都远高于随机读写,这种差距甚至可以达到三个数量级,其中,内存的随机读写性能是最高的。如下图(注意对数坐标)
二、思路
假设现在重新设计一个时序数据库:
因为硬盘和内存的大小总是有限的,如果能尽量少的存储数据,就可以极大的降低成本。而且同一个数据源上报的数据的标签值总是一致的。在存储数据中心内所有服务器 CPU 分核心使用率这个场景中,数据中发生变化的只有时间和值。那么标签只需要存一次。
可以把拥有同样标签的数据称之为一个系列。
根据这个思路改造一下上面的表,拆分成两张:
方案一:
系列表:
| 编号 | 标签值 |
| 1 | IP=192.168.1.1;CPU=#0 |
| 2 | IP=192.168.1.1;CPU=#1 |
数据表:
| 系列编号 | 时间 | 使用率 |
| 1 | 5 | 1 |
| 2 | 5 | 17 |
| 1 | 6 | 3 |
| 2 | 6 | 15 |
因为查询请求总是类似 「找出过去十分钟 192.168.1.1 #0 CPU核的使用率」这样的针对一个系列的查询。而连读写总是比随机读写要快得多得多。那么把一个系列的数据组织到一起将会有很大的益处。再改造一下设计,把数据按系列拆分开:
方案二:
系列表:
| 表号 | 标签值 |
| 1 | IP=192.168.1.1;CPU=#0 |
| 2 | IP=192.168.1.1;CPU=#1 |
表①:
| 时间 | 使用率 |
| 5 | 1 |
| 6 | 3 |
表②:
| 时间 | 使用率 |
| 5 | 17 |
| 6 | 15 |
但是,这导致了写变成随机操作。
因为内存是所有存储设备中随机性能最好的,可以利用内存先存起来,再改一改方案二。
方案二A:
把数据先按方案二写到内存上,攒一段时间的数据再统一写到硬盘上。
似乎很完美了。
但是,假如在内存上的数据写入硬盘之前发生了意外断电,这些数据就会丢失。继续改方案二。
方案二B:
写入内存的同时,也按照 方案一中数据表 的形式写一份到硬盘中,把它称之为 WAL(Write-ahead logging),对硬盘来说是连续写,可以有很好的性能 。内存和硬盘上的两份数据都写入成功才是成功。
如果发生断电,程序重启后先读取硬盘上的 WAL,恢复内存中尚未写入硬盘的数据。虽然读取 WAL 恢复内存结构的成本比较高,但断电并不总是发生。
三、InfluxDB 是怎么干的
InfluxDB 的做法是类似的:
func (e *Engine) WritePoints(ctx context.Context, points []models.Point) error {
// 略去预处理代码
// first try to write to the cache
if err := e.Cache.WriteMulti(values); err != nil {
return err
}
if e.WALEnabled {
if _, err := e.WAL.WriteMulti(ctx, values); err != nil {
return err
}
}
return seriesErr
}
先写入了内存上的 Cache,然后写入硬盘上的 WAL两者都写入成功后才返回。
最后:我们根据时序数据和计算机本身的特点重新梳理了思路,反推出了与 InfluxDB 类似的方案 。虽然一直在用关系数据库中的表进行说明,但是这并不表示 InfluxDB 使用关系数据库做为其存储引擎。在下一篇文章中将了解如何把 InfluxDB 在自己的机器上编译运行起来,进行断点调试,并详细的探索 InfluxDB 中 Cache 的结构。
扩展阅读:
- 连续操作 VS 随机操作:缓存亲和性(cache affinity)
- 行存、列存、数据布局:CMU Advanced Database Systems - 10 Storage Models & Data Layout
- Paul Dix 在 CMU 做的关于 InfluxDB 的介绍,解释了早期 InfluxDB 的各种技术选型及遇到的问题:Time Series Database Lectures #1 - Paul Dix (InfluxDB)
- InfluxDB 的这个技术方案叫做 TSM-Tree ,受到了 LSM-Tree 的启发,LSM 原始论文:The Log-Structured Merge-Tree (LSM-Tree)

文章评论