一些名词
- 点(Point):一条记录,类似 SQL 中的一行。如:host A 在 Unix 时间 1000 的 CPU load 是 1.1 包含的信息就是一个点。
- 行协议(InfluxDB line protocol):一种方便的表述点的方法,如上文的提到的点根据行协议就可以简单写成cpu,host=A value=1.1 100
- 系列(Series):一组只有时间和值不同的点,如cpu,host=A value=1.1 1000,cpu,host=A value=2.3 1010 这两个点代表不同时间的 host a 的 CPU load,它们就属于一个系列。
更多请参考 InfluxDB 词汇表
前文提要
上一篇提到,时序数据的常见写入模型是多个系列同时写入少量点,而常见读取模式是单个系列连续读取大量点,这就导致了无论采用行存还是列存的方式都会在读或写的一侧出现随机操作,这会对延迟和吞吐量造成极大的影响,而内存和硬盘各有所长:
-
内存 -
随机操作性能相比硬盘好很多 -
断电即丢数据
-
-
硬盘 -
顺序操作性能很好 -
随机操作性能很差,即便是 SSD -
断电也不丢数据
-
所以在数据到来的时候,需要写两份:
-
先在内存中根据系列整理,一段时间后再统一落盘 -
不做任何整理直接写入硬盘,用于断电时恢复内存数据中还未来得及落盘的数据
如何在内存中高效的把点按系列整理就是非常有挑战的工作。这个过程不可避免会使用到锁,如果锁的粒度太大,会极大的影响系统的吞吐量。锁粒度、锁顺序控制就是非常重要的课题。
从需求出发
基础结构
一个点就是系列+时间+值,并且值的类型并不是固定的,点的数据结构:
type Point struct {
Series string
Time uint64
Value any
}
用户输入了六个点:
func F32Point(f float32) *float32 { return &f }
p1 := Point{Series: "CPU#host=A", Time: 100, Value: F32Point(1.1)}
p2 := Point{Series: "CPU#host=B", Time: 100, Value: F32Point(2.3)}
p3 := Point{Series: "CPU#host=C", Time: 100, Value: F32Point(1.4)}
p4 := Point{Series: "CPU#host=A", Time: 200, Value: F32Point(3.1)}
p5 := Point{Series: "CPU#host=B", Time: 200, Value: F32Point(5.3)}
p6 := Point{Series: "CPU#host=C", Time: 200, Value: F32Point(1.5)}
points := []Point{p1, p2, p3, p4, p5, p6}
考虑把 `points` 按 `Series` 分类,很容易想到的方法就是使用 `map[string][]Point` ,把 `Series` 做为key,value 是 `Point` 切片。一个显著的问题是Series 对一个系列的点来说都是一致的,反复存储浪费宝贵的内存空间。增加 `PointValue` 结构,使用 `map[string][]PointValue` 来存储,只保留变化的时间和点值。
type PointValue struct {
Time int64
Value any
}
func NewPointValue(p Point) PointValue {
return PointValue{Time: p.Time, Value: p.Value}
}
在开始思考如何优化锁粒度之前,首先需要了解的是:多协程只读不会产生冲突,多协程读写才会产生冲突。
一把大锁
最简的方案就是对整个 map[string][]PointValue 加一把大锁。
模拟多协程写:
var mu sync.Mutex
m := make(map[string][]PointValue)
for _, point := range points {
go func(p Point) {
mu.Lock()
defer mu.Unlock()
values, ok := m[p.Series]
if ok {
m[p.Series] = append(values, NewPointValue(p))
} else {
m[p.Series] = []PointValue{NewPointValue(p)}
}
}(point)
}
对于多个系列同时写入少量点,并且系列几乎不变,这样的写入模式来说,可以认为大部分时候都会走到 m[p.Series] = append(values, NewPointValue(p)) 这个分支中。可以把这个语句拆分为两个动作
-
把点加到 Values -
回写 map
只有回写的这一步才会与其他协程冲突,让 map 持有指针而不是值可以避免回写。
按系列锁
增加一个结构,并把原来的 map[string][]PointValue 改成 map[string]*SeriesValues
type SeriesValues struct {
L sync.Mutex
Values []PointValue
}
func (s *SeriesValues) WritePoint(p Point) {
s.L.Lock()
defer s.L.Unlock()
s.Values = append(s.Values, NewPointValue(p))
}
并把 map 的锁改成读写锁。
上一段代码改成:
var mu sync.RWMutex
m := make(map[string]*SeriesValues)
for _, point := range points {
go func(p Point) {
mu.RLock()
sv, ok := m[p.Series]
mu.RUnlock()
if ok {
sv.WritePoint(p)
return
}
mu.Lock()
defer mu.Unlock()
// 再次检查
if sv, ok := m[p.Series]; ok {
sv.WritePoint(p)
return
}
m[p.Series] = &SeriesValues{Values: []PointValue{NewPointValue(p)}}
}(point)
}
当所有系列都在 map 中有「一席之地」之后,写入点都会进入第一个 if 中,系列之间的写入没有冲突。需要注意第二个 if 语句,拿到写锁准备写入 map 之前,必须再次检查系列是否存在。因为在当前协程获取到写锁之前,可能有协程先抢到写锁,如果直接写入,就会丢失别的协程先写入的数据。
还有一个问题,map 刚刚初始化时,几乎所有的写入都需要抢写锁,性能会很差。 需要降低初始化时冲突的概率。
分片
可以分开使用多个 map 来存储,使用数组来组织这些 map,形成[16]map[string]*SeriesValues的结构。在插入 map 之前先进行一次 hash ,在数组中选择一个 map 来写入。在数组初始化后不会再有修改动作,那么在读数组这一层不需要锁,也不会有任何的冲突。假设数组长度为 16 位创建一个系列的冲突概率就变成了原来的 1/16 。
// 先把 map[string]*SeriesValues 组织成一个结构体
type Partition struct {
Mu sync.RWMutex
Store map[string]*SeriesValues
}
func (p *Partition) WritePoint(point Point) {
p.Mu.RLock()
sv, ok := p.Store[point.Series]
p.Mu.RUnlock()
if ok {
sv.L.Lock()
defer sv.L.Unlock()
sv.Values = append(sv.Values, NewPointValue(point))
return
}
p.Mu.Lock()
defer p.Mu.Unlock()
// 再次检查
if sv, ok := p.Store[point.Series]; ok {
sv.L.Lock()
defer sv.L.Unlock()
sv.Values = append(sv.Values, NewPointValue(point))
return
}
}
var cache [16]*Partition
// 省略初始化步骤
for _, point := range points {
go func(p Point) {
hash := xxhash.Sum64String(p.Series) % uint64(16)
partition := cache[hash]
// 所有的操作对 cache 都是只读的,不需要锁
partition.WritePoint(p)
}(point)
}
只读不需要锁和分片这样的思路是非常通用的。在控制好分片的粒度后,可以很大程度的避免锁。
例如:代理转发服务,需要累加计算转发的 byte 数,最大允许并发为 1000。 可以用 sync/atomic 包。 也可以预先分配一个 [1000]int 数组,连接初始化时获取一个 id,只累加对应 offset 的数据。最后对 [1000]int 求和即可。
InfluxDB 里的结构
Cache 结构体的源代码在 influxdb/tsdb/engine/tsm1/cache.go 下
如果写入这三个点:
cpu,host=A value=1.1 1000000000
cpu,host=A value=1.2 2000000000
cpu,host=A value=1.3 3000000000
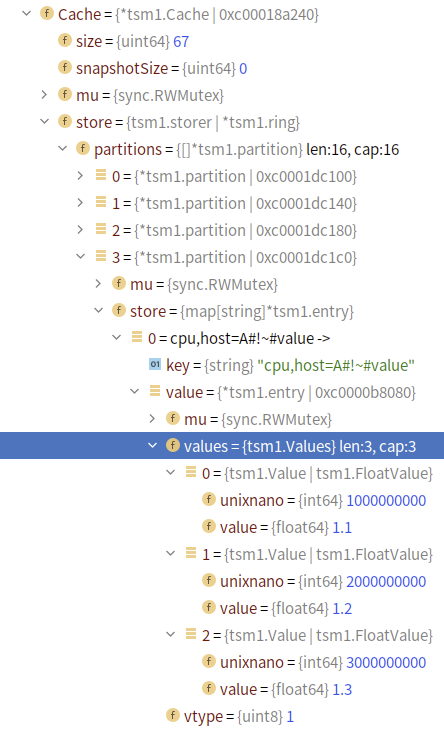
从结构上看,和前文分析的结构是基本一致的。
摘录部分代码,可以根据 结构体名在上图中对应找到:
-
先初始化一个定长数组,根据 key 的 hash 值决定写入的分片。
type ring struct {
partitions []*partition
}
func (r *ring) getPartition(key []byte) *partition {
return r.partitions[int(xxhash.Sum64(key)%uint64(len(r.partitions)))]
}
- 先判断序列是否存在,存在则直接写,不存在再加写锁新增一个序列。
type partition struct {
mu sync.RWMutex
store map[string]*entry
}
func (p *partition) write(key []byte, values Values) (bool, error) {
p.mu.RLock()
e := p.store[string(key)]
p.mu.RUnlock()
if e != nil {
// Hot path.
return false, e.add(values)
}
p.mu.Lock()
defer p.mu.Unlock()
// Check again.
if e = p.store[string(key)]; e != nil {
return false, e.add(values)
}
// Create a new entry using a preallocated size if we have a hint available.
e, err := newEntryValues(values)
if err != nil {
return false, err
}
p.store[string(key)] = e
return true, nil
}
- 分系列锁,尽可能降低锁粒度
type entry struct {
mu sync.RWMutex
values Values // All stored values.
// The type of values stored. Read only so doesn't need to be protected by
// mu.
vtype byte
}
func (e *entry) add(values []Value) error {
if len(values) == 0 {
return nil // Nothing to do.
}
// Are any of the new values the wrong type?
if e.vtype != 0 {
for _, v := range values {
if e.vtype != valueType(v) {
return tsdb.ErrFieldTypeConflict
}
}
}
// entry currently has no values, so add the new ones and we're done.
e.mu.Lock()
if len(e.values) == 0 {
e.values = values
e.vtype = valueType(values[0])
e.mu.Unlock()
return nil
}
// Append the new values to the existing ones...
e.values = append(e.values, values...)
e.mu.Unlock()
return nil
}
下一篇将探讨 WAL 的写入和恢复过程。

文章评论